Retrieval-augmented generation (RAG) को अगर बहुत सिंपल भाषा में समझें, तो ये “LLM + आपका अपना दिमाग वाला डेटा” है – ताकि AI जवाब दे भी इंसान की तरह, और facts भी आपके सिस्टम से उठा कर दे, न कि सिर्फ अपने ट्रेनिंग डेटा पर भरोसा करे।
RAG आखिर है क्या?
- LLM (जैसे GPT, Gemini आदि) अपने ट्रेनिंग डेटा के आधार पर जवाब देते हैं – ये डेटा फिक्स होता है और एक डेट तक ही अपडेटेड होता है।
- RAG इस LLM के सामने एक और लेयर जोड़ देता है: पहले आपका सवाल लिया जाता है, फिर आपके डॉक्यूमेंट्स/डेटाबेस में से related जानकारी “retrieve” की जाती है, और फिर ये context LLM को साथ में दिया जाता है ताकि वो grounded, fact-based जवाब दे सके।
यानि:
User का सवाल → Relevant data निकालो → इस data से prompt को augment करो → LLM grounded जवाब generate करे।
अगर आप SEO को “scaled human decision-making” मान रहे थे, तो RAG को आप “scaled, context-aware human expert” मान सकते हैं – जो हर जवाब देने से पहले आपके खुद के knowledge base से cross-check कर लेता है।
क्यों ज़रूरत पड़ी RAG की?
LLM अपने आप में बहुत power रखते हैं, लेकिन इनकी कुछ fundamental लिमिटेशन हैं:
- पुराना knowledge: मॉडल एक fixed dataset तक train होता है, उसके बाद की दुनिया इसे नहीं पता।
- Hallucination: जब जवाब नहीं पता होता, तो भी कुछ “confidence से” बोल देता है – जो दिखने में सही लगे, पर होता गलत है।
- Generic जवाब: आपके business के specific rules, policies, pricing, compliance वगैरह मॉडल को नहीं पता होते।
- Sensitive / internal data: LLM के ट्रेनिंग सेट में आपका private database तो हो नहीं सकता – और होना भी नहीं चाहिए।
RAG इन gaps को भरने की कोशिश करता है:
- LLM को आपके internal knowledge base, enterprise systems, FAQs, policies, CRM data आदि से connect करके।
- ताकि हर जवाब से पहले मॉडल “fresh, trusted, authoritative” sources से डेटा उठा के बोले।
AWS इसे ऐसे define करता है: LLM के output को optimize करना ताकि वो training data के बाहर भी किसी authoritative knowledge base को reference करके जवाब दे सके – बिना हर बार model retrain किए।
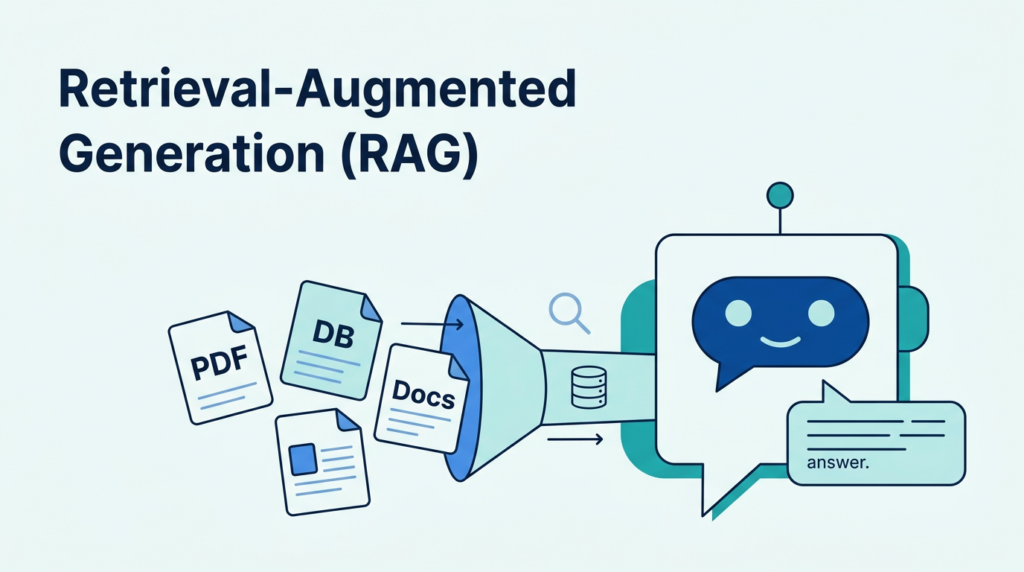
RAG कैसे काम करता है? (End‑to‑end फ्लो)
एक typical RAG सिस्टम के अंदर की journey कुछ ऐसी दिखती है:
- User का सवाल आता है
- Chat, web form, API, WhatsApp bot – कहीं से भी query आती है।
- Query को “retrieval friendly” बनाया जाता है (optional but useful)
- Query को rewrite, compress या translate किया जाता है ताकि search engine/vector store को समझ आए कि असल में ढूंढना क्या है।
- जैसे Spring AI में CompressionQueryTransformer, RewriteQueryTransformer, TranslationQueryTransformer यही काम करते हैं।
- Data sources से relevant content “retrieve” किया जाता है
- Internal docs: policies, manuals, knowledge base, tickets, emails।
- Databases / APIs: CRM, billing, HRMS, loan systems, etc।
- ये सब vector database या search engine के through semantic / hybrid search से आता है।
- Retrieved docs को process किया जाता है
- Chunking, filtering, re-ranking, noise हटाना, duplicates हटाना, context length के हिसाब से trimming।
- Query + retrieved content को merge करके “augmented prompt” बनाया जाता है
- यहीं पर RAG असल में “retrieval-augmented generation” बनता है – user का सवाल और साथ में curated context, एक अच्छे prompt template में pack किया जाता है।
- LLM इस augmented prompt के basis पर जवाब generate करता है
- अब मॉडल का काम सिर्फ language और reasoning का है; facts आपने ऊपर retrieval pipeline से दे दिए।
- (Optional) Source citation / guardrails
- Output में citations, references, guardrails (जैसे: अगर context नहीं मिला तो “I don’t know” कहना) add किए जाते हैं।
Google इसे दो बड़े स्टेप में summarize करता है: retrieval + grounded generation.
RAG की core building blocks (simple language में)
1. Data sourcing और तैयारी
सबसे पहले सवाल आता है: AI को खिलाएंगे क्या? RAG में data दो तरह से आता है:
- Unstructured: PDFs, docs, FAQs, emails, manuals, tickets, chats।
- Structured / semi-structured: DB tables, CRM records, spreadsheets, JSON, XML आदि।
इन्हें RAG‑friendly बनाने के लिए:
- Clean, dedupe, metadata add – ताकि बाद में filter और security policies लग सकें।
- Access control / masking – कौन क्या देख सकता है, ये यहीं decide होता है।
2. Chunking और embeddings
Unstructured docs को छोटे-छोटे chunks में तोड़ा जाता है – sections, paragraphs, Q&A snippets वगैरह – ताकि:
- Retrieval ज्यादा precise हो;
- Prompt में सिर्फ relevant हिस्सा जाए, पूरा 200-page PDF नहीं;
- Cost और latency दोनों control में रहें।
फिर हर chunk पर embedding model run होता है – text को एक numerical vector में बदल कर vector database में store कर दिया जाता है।
3. Retrieval: semantic / hybrid search
जब user query आती है:
- Query का भी embedding बनता है;
- Vector DB में semantic similarity के basis पर top‑K chunks निकाले जाते हैं;
- Modern systems (Vertex AI Search, Amazon Kendra आदि) semantic + keyword दोनों का hybrid search करते हैं और re-ranker से सबसे relevant चीजें ऊपर लाते हैं।
Spring AI में ये काम VectorStoreDocumentRetriever जैसे components करते हैं – जिसमें similarity threshold, topK, filters सब control कर सकते हैं।
4. Query transformation और expansion (pre‑retrieval)
कुछ extra “smartness” यहीं पर आती है:
- Rewrite queries: user की vague query को search-friendly बनाना।
- Compress follow-up questions: लम्बी chat history से core question निकालना।
- Translate: अगर embeddings सिर्फ English पर trained हैं और query Hindi में है तो पहले translate करना।
- Multi-query expansion: एक query को कई अलग-अलग angles से expand करना ताकि ज्यादा rich context मिले।
5. Document post-processing (post‑retrieval)
Retrieved documents को भी raw रूप में LLM को देना जरूरी नहीं है:
- Re-rank based on query;
- Irrelevant या duplicate chunks हटाना;
- Compress / summarize chunks ताकि context window में fit हो जाएं।
6. Query augmentation और generation
अब core step: ContextualQueryAugmenter जैसे components user query के साथ retrieved content को merge करके एक prompt बनाते हैं।
Template का pattern अक्सर कुछ ऐसा होता है:
- ऊपर user का सवाल;
- नीचे “Context information” के section में सारे relevant chunks;
- Instruction: “अगर जवाब context में नहीं है तो साफ बोलो कि नहीं पता; hallucinate मत करो।”
इस तरह LLM language और reasoning का काम करता है, facts context से लेता है।
RAG vs सिर्फ semantic search vs fine‑tuning
बहुत लोगों को ये तीनों चीजें mix लगती हैं, so साफ-cut view:
Google और AWS दोनों मानते हैं कि अगर आपको fresh internal data, citations और control चाहिए, तो direct fine‑tuning की बजाए RAG ज़्यादा practical और cost-effective है।
RAG के फायदे – business language में
1. Cost और speed
- Foundation models को retrain / fine‑tune करना महंगा और slow है, खासकर जब data अक्सर बदलता हो (rates, offers, policies)।
- RAG में model वही रहता है – आप सिर्फ retrieval pipeline और knowledge base update करते हैं, जो ज़्यादा fast और सस्ता है।
2. Fresh, real-time information
- LLM का ट्रेनिंग cutoff issue bypass हो जाता है – आप RAG के जरिए live systems (APIs, DBs, event streams) से data ला सकते हैं।
- जैसे: latest commissions, current leave balance, current loan eligibility norms, etc।
3. Trust और explainability
- Output के साथ citations / references आ सकते हैं – user देख सकता है कि जवाब किन documents या records पर based है।
- इससे hallucination risk कम और trust ज़्यादा बनता है, खासकर compliance / legal / finance जैसे areas में।
4. Developer control और governance
- आप decide करते हैं कि मॉडल कौन से sources पढ़ेगा, किस level के user को क्या दिखेगा, कौन सा field mask होगा।
- अगर गलत source pick हो जाए, pipeline में fix कर सकते हैं – model weights छूने की ज़रूरत नहीं।
Challenges – ground reality
RAG सुनने में clean architecture लगती है, लेकिन enterprise level पर complexities हैं:
- Fragmented data: Billing, CRM, ERP, ticketing, HRMS – data हर जगह बिखरा है; single customer का 360° view बनाना खुद में बड़ा project है।
- Data quality & metadata: अगर metadata weak है, governance नहीं है, redundancy है – retrieval कमजोर होगा, और AI भी।
- Latency: Chat interface में आपको 1-2 सेकंड में जवाब चाहिए; ये तभी possible है जब retrieval pipeline optimized हो।
- Security & privacy: RBAC, dynamic masking, tenant isolation – ये सब नहीं किया तो RAG से आप गलती से गलत user को गलत PII दिखा सकते हैं।
- Skills: Data engineering, search, embeddings, prompt engineering, infra – ये सब capabilities एक साथ चाहिए।
इसीलिए Gartner और Forrester दोनों recommend करते हैं कि enterprises पहले high-ROI pilot use cases से शुरू करें, और फिर धीरे-धीरे broader adoption की तरफ जाएं।
Typical RAG use cases (day‑to‑day examples)
K2view, Google, AWS वगैरह के examples को मिलाकर देखें, तो RAG आज mainly इन scenarios में use हो रहा है:
- Customer service copilot / chatbot
- Agent के सामने live customer 360, policies, past tickets, FAQs – सब context में डाल कर suggested answers देना।
- Sales & marketing assistants
- Product docs + customer profile + campaigns से मिलाकर personalized pitch या next-best-offer generate करना।
- Internal “AI wiki” / knowledge assistant
- Employees के लिए policies, HR docs, engineering docs, SOPs – सब पर Q&A, citations के साथ।
- Compliance & legal
- Regulations + internal approvals + customer data को मिलाकर DSAR responses या compliance summaries बनाना।
- Risk & fraud
- Past fraud patterns + real-time transactions से suspicious behaviour पर explainable summaries।
Google का broader view: कोई भी agent / chatbot जो fresh, private या specialized data पर निर्भर है, वहां RAG + grounding almost default architecture बन रहा है।
Tech examples: Spring, AWS, Google
आप जैसे product/tech background वाले के लिए कुछ concrete references काम आएंगे।
Spring AI की modular RAG thinking
Spring AI RAG को pure “pipeline of modules” मान कर design करता है:
- Pre‑retrieval: Query transformers, multi-query expanders।
- Retrieval: VectorStoreDocumentRetriever, filters, metadata-based search।
- Post‑retrieval: Document post-processing, re-ranking।
- Generation: ContextualQueryAugmenter से augmented prompts।
ऊपर Advisor APIs (QuestionAnswerAdvisor, RetrievalAugmentationAdvisor) के through आप naive से लेकर advanced flows बना सकते हैं – जैसे filters per tenant, allowEmptyContext, custom prompt templates, आदि।
AWS का RAG view
AWS RAG को ऐसी capability के रूप में दिखाता है जो foundation models के ऊपर बैठकर:
- External data को embeddings में convert करके vector DB में store करता है;
- Query को vector में बदलकर relevant passages retrieve करता है;
- इन्हीं passages को prompt में जोड़ कर जवाब बनाता है;
- Knowledge bases for Amazon Bedrock और Amazon Kendra जैसी services से ये काम almost managed तरीके से कर सकता है।
Google Cloud और “grounded generation”
Google RAG को grounded generation से जोड़कर देखता है – LLM को आपके curated knowledge base से facts देकर hallucinations minimize करना।
- Vertex AI Search + RAG infra;
- Hybrid search (semantic + keyword) + re-ranker;
- Evaluation metrics (coherence, groundedness, safety, etc.) से RAG quality को continuous measure और improve करना – RAG Ops के angle से।
RAG को practically सोचने का तरीका
आपकी SEO वाली analogy याद रखते हुए, RAG को ऐसे imagine कर सकते हैं:
- बिना RAG के LLM = ऐसा writer जो दुनिया की सारी generic जानकारी पढ़ चुका है, लेकिन आपके business को नहीं जानता, न current data को;
- RAG वाला LLM = वही writer, लेकिन हर answer से पहले आपके CRM, knowledge base, docs, dashboards आदि से latest data pull करके देखता है, और फिर बोलता है।
इससे:
- Content सिर्फ “nice language” नहीं, बल्कि आपके actual numbers, rules, T&Cs पर based होता है;
- User को दो चीजें मिलती हैं: conversational experience + trustworthy, explainable facts।